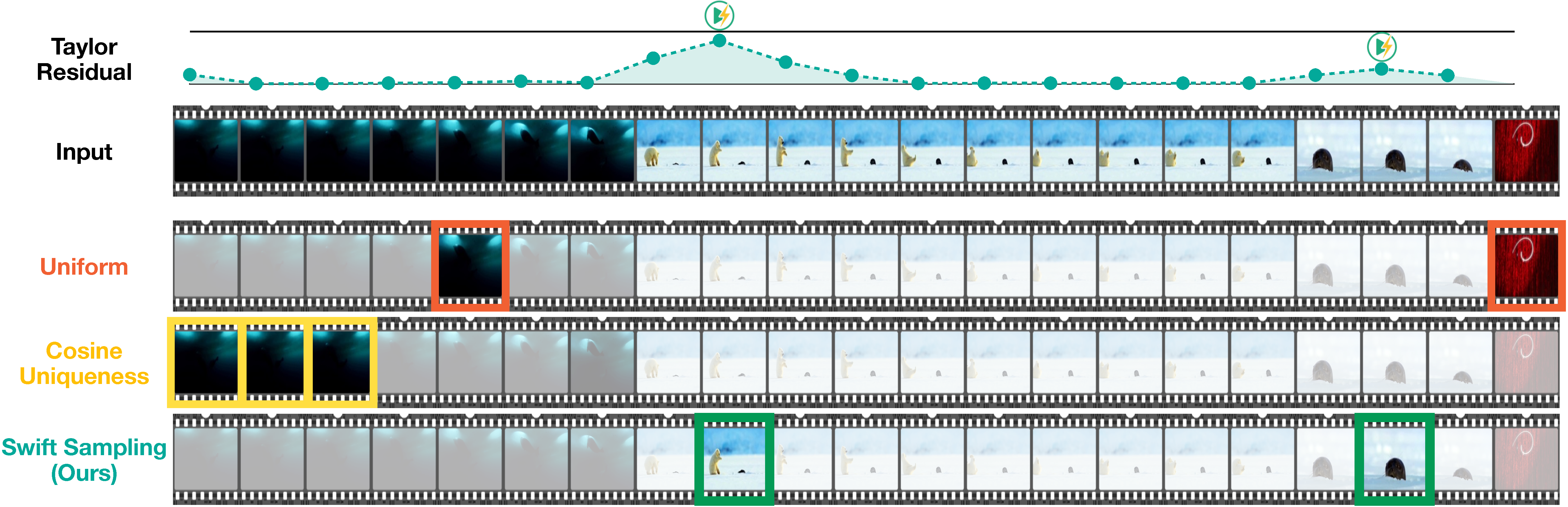
While most frames in long-form video are redundant, the critical information resides in temporal surprises: moments where the actual visual features deviate from their predicted evolution. Inspired by the human brain's predictive coding, we introduce Swift Sampling, an elegant, training-free frame selection algorithm that automatically identifies high-information moments in a video. Specifically, we model a video as a differentiable trajectory in the visual latent space and compute the velocity and acceleration of its features. Then, we apply Taylor expansion to project the expected path of subsequent frames. Frames that diverge sharply from this predicted manifold are identified as temporally surprising frames and selected for sampling.
Unlike prior training-free methods that rely on auxiliary networks or video-specific hyperparameter tuning, Swift Sampling is incredibly lightweight, adding only 0.02× additional computational cost over the baseline, making it 30× cheaper in overhead than leading baselines. Across three long-video question answering benchmarks and 10 different downstream tasks, Swift Sampling outperforms uniform sampling and prior query-agnostic baselines. It is especially powerful for long videos with limited frame budgets, improving accuracy by up to +12.5 points.
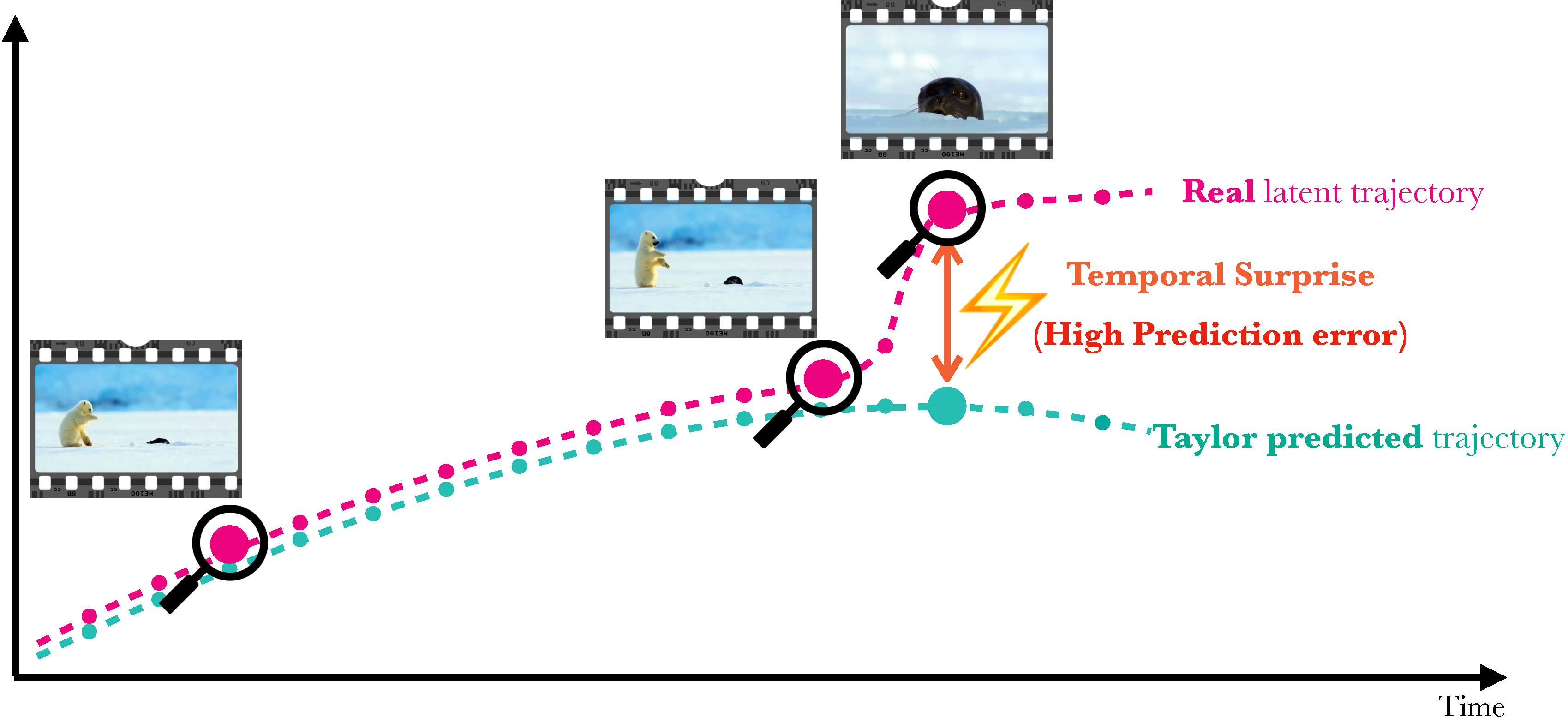
Our method is based on a simple observation: long-form video consists of vast, highly predictable intervals interjected with sparse temporal surprises. Swift Sampling treats the visual latent features of adjacent video frames as points lying on a locally smooth trajectory (Figure 2). This makes it amenable to a polynomial approximation via Taylor series using higher-order derivatives. Given the feature vectors of the N frames preceding the current frame t, we construct a Taylor predictor that captures the velocity (first order), acceleration (second order), and jerk (third order) of the feature trajectory. The Taylor residual is the ℓ2 distance between the predicted feature f̂t(N) and the observed feature ft:
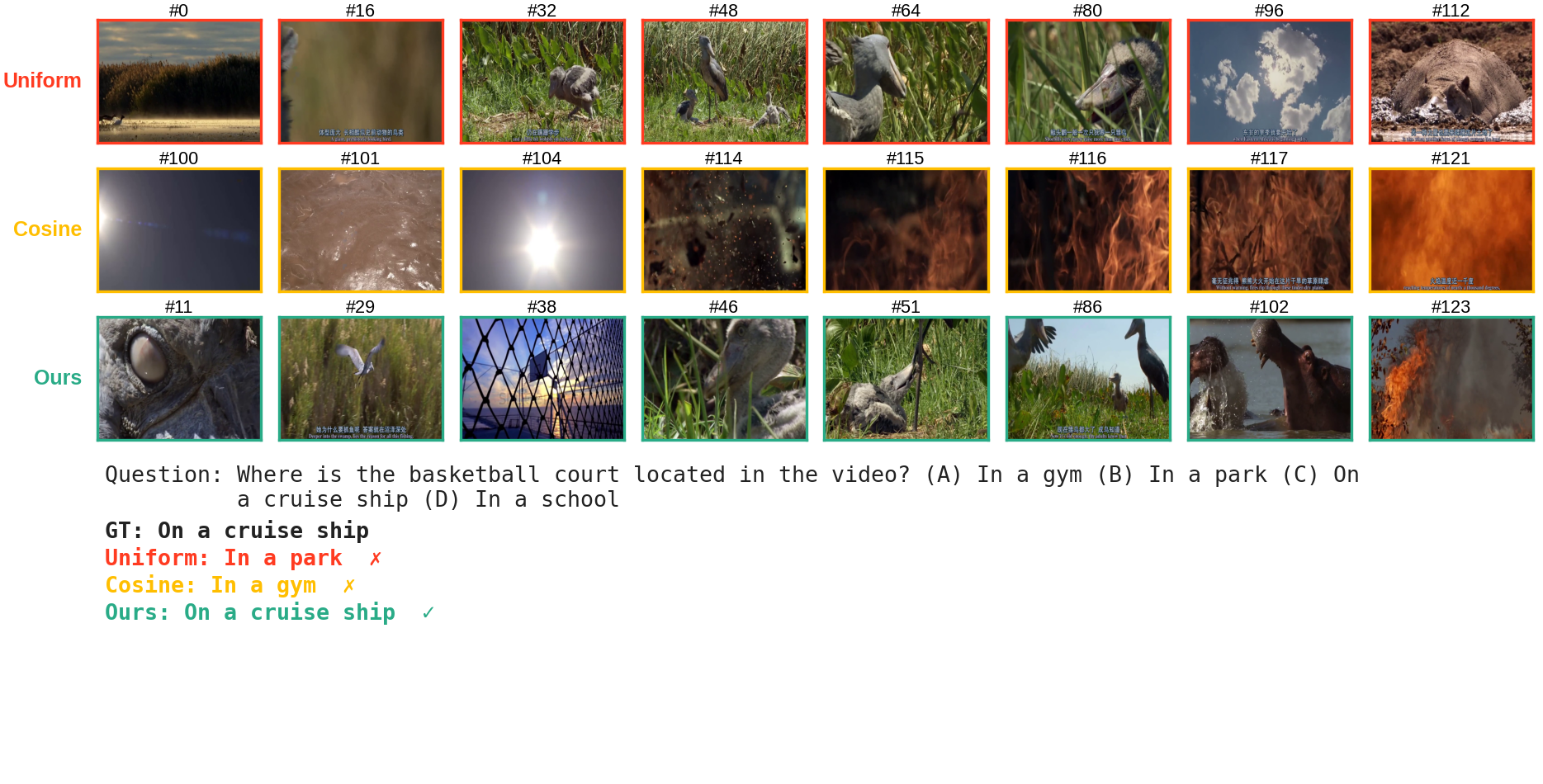
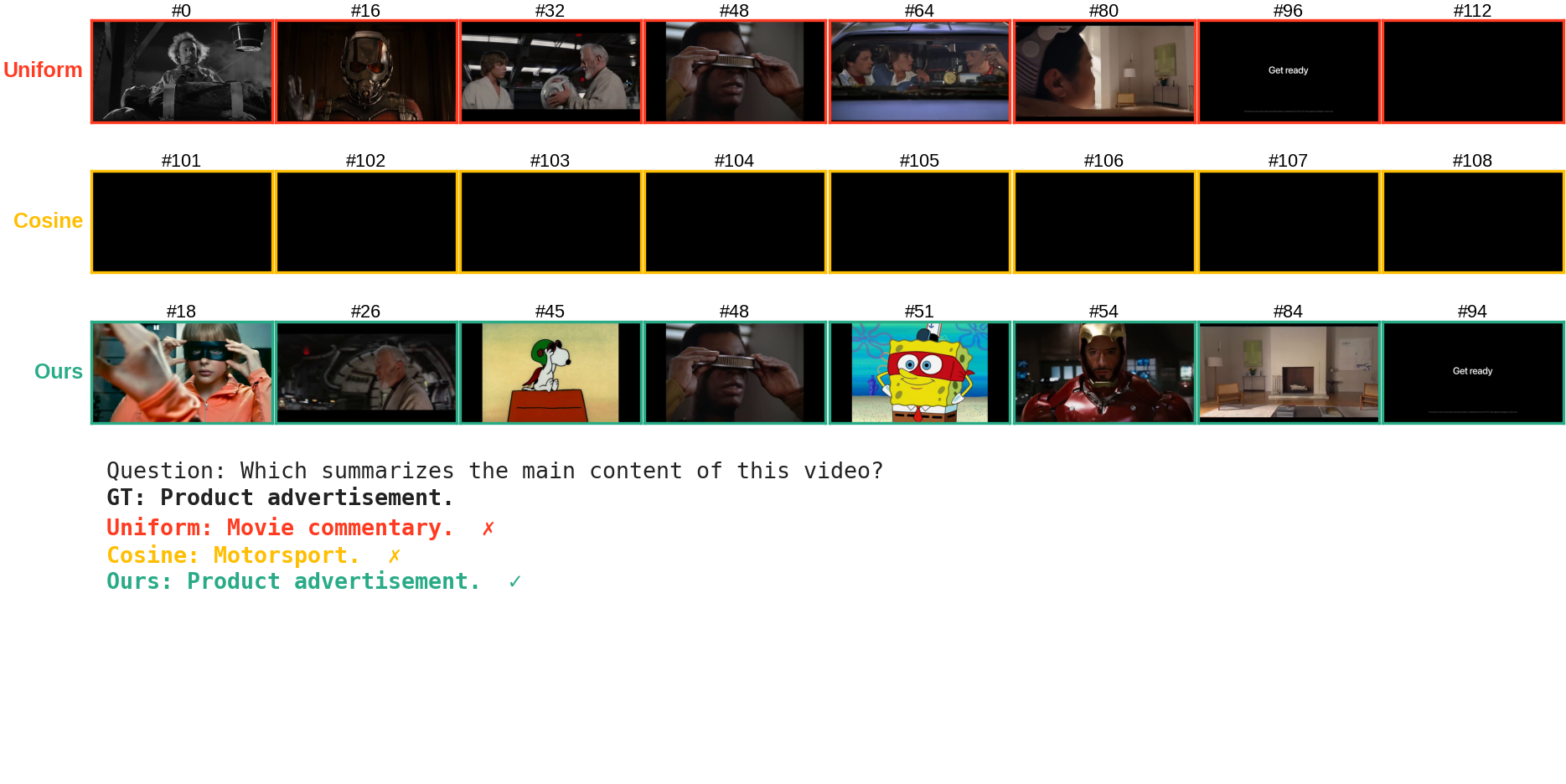
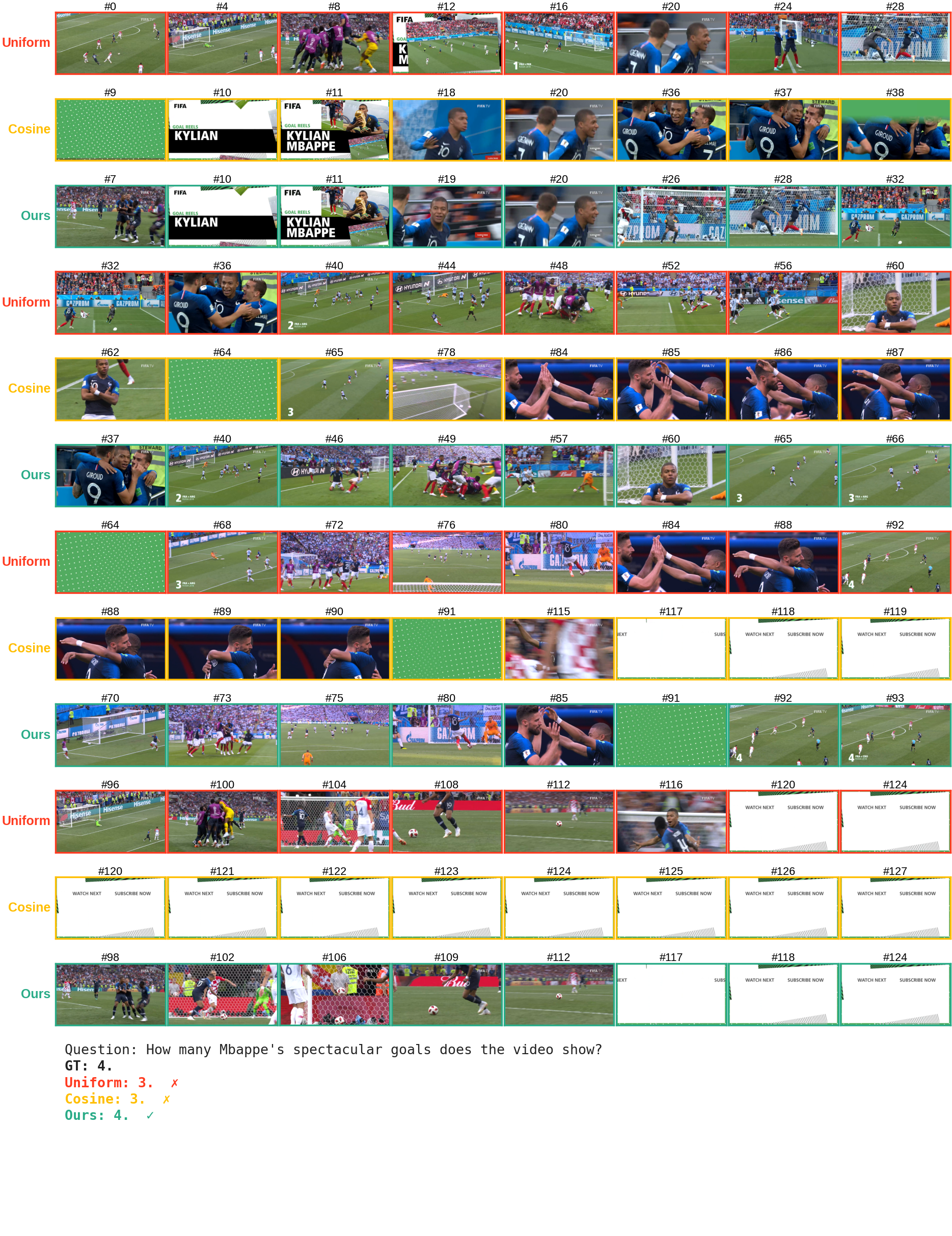
It serves as a principled, per-frame informativeness score. A small residual indicates a predictable, redundant frame (e.g., a bear's rhythmic walk), while a large residual signals a temporal surprise, i.e., a moment of genuinely new information (e.g., the sudden emergence of a seal out of the ice). For a given frame budget K, we select the K local maxima of the residual sequence, prioritizing the most surprising frame within each local temporal context. The sampling rate scales naturally with the video complexity, making our approach hyperparameter-light. Crucially, we compute these residuals directly from the intermediate representations of the VLM's vision encoder that must be computed anyway during the forward pass.
VQA accuracy across different video durations on Video-MME, LongVideoBench (LVB), and MLVU. All methods select 32 frames from a pool of 128. FLOPs report inference cost relative to uniform sampling.
| Method | FLOPs | Video-MME | LongVideoBench | MLVU | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Short | Med. | Long | Overall | ≥10m | ≥20m | ≥30m | Overall | ≥10m | ≥15m | ≥30m | Overall | ||
| LLaVA-OneVision | |||||||||||||
| Uniform | 1.00× | 69.9 | 56.4 | 48.8 | 58.3 | 45.2 | 47.5 | 48.1 | 55.3 | 61.4 | 54.4 | 50.0 | 64.7 |
| Cosine Uniqueness | 1.60× | 65.3 | 54.7 | 47.0 | 55.7 | 47.0 | 47.1 | 46.3 | 52.5 | 63.6 | 61.1 | 47.9 | 65.4 |
| Swift Sampling (Ours) | 1.02× | 71.0 | 56.9 | 49.2 | 59.0 | 51.6 | 54.3 | 50.9 | 57.9 | 62.2 | 58.2 | 54.2 | 65.6 |
| LLaVA-Video | |||||||||||||
| Uniform | 1.00× | 74.0 | 59.0 | 51.3 | 61.4 | 50.7 | 53.3 | 54.6 | 56.8 | 56.7 | 54.4 | 50.0 | 64.2 |
| Cosine Uniqueness | 1.60× | 69.2 | 54.4 | 50.1 | 57.9 | 50.7 | 52.5 | 54.6 | 56.5 | 61.2 | 57.0 | 50.0 | 66.5 |
| Swift Sampling (Ours) | 1.02× | 74.9 | 59.1 | 51.6 | 61.9 | 52.1 | 56.2 | 57.4 | 58.6 | 60.0 | 55.0 | 52.1 | 67.2 |
Swift Sampling brings consistent gains over uniform sampling on both backbones, with particularly strong improvements on long-duration videos: +6.8 points on LongVideoBench (≥20 min) and +4.2 points on MLVU (≥30 min) for LLaVA-OneVision, at only 1.02× inference cost.
All methods select 32 frames from a pool of 128 on LLaVA-OneVision. FLOPs report inference cost relative to uniform sampling.
| Method | FLOPs | Video-MME | LongVideoBench | MLVU | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Short | Med. | Long | Overall | ≥10m | ≥20m | ≥30m | Overall | ≥10m | ≥15m | ≥30m | Overall | ||
| Uniform | 1.00× | 69.9 | 56.4 | 48.8 | 58.3 | 45.2 | 47.5 | 48.1 | 55.3 | 61.4 | 54.4 | 50.0 | 64.7 |
| Cosine Uniqueness | 1.60× | 65.3 | 54.7 | 47.0 | 55.7 | 47.0 | 47.1 | 46.3 | 52.5 | 63.6 | 61.1 | 47.9 | 65.4 |
| Frame difference | 1.00× | 67.4 | 53.3 | 48.3 | 56.4 | 46.3 | 49.3 | 51.9 | 53.5 | 58.5 | 53.7 | 45.8 | 64.6 |
| Iframe | 1.00× | 67.4 | 54.9 | 48.7 | 57.0 | 52.0 | 49.8 | 49.8 | 57.1 | 60.6 | 54.4 | 52.1 | 63.8 |
| Pframe | 1.00× | 66.9 | 55.1 | 48.2 | 56.7 | 51.9 | 49.1 | 49.1 | 56.5 | 60.8 | 54.4 | 50.0 | 64.1 |
| Optical Flow | 1.07× | 68.6 | 53.0 | 48.0 | 56.5 | 52.4 | 50.7 | 50.7 | 56.9 | 60.0 | 56.4 | 52.1 | 62.9 |
| DySeg (adapted) | 1.79× | 69.6 | 53.7 | 48.4 | 57.2 | 46.0 | 48.2 | 51.9 | 52.9 | 49.6 | 47.7 | 48.3 | 63.1 |
| MaxInfo | 1.79× | 71.1 | 57.2 | 48.8 | 58.9 | 51.4 | 50.8 | 50.0 | 57.8 | 63.0 | 59.1 | 51.1 | 66.5 |
| Swift Sampling (Ours) | 1.02× | 71.0 | 56.9 | 49.2 | 59.0 | 51.6 | 54.3 | 50.9 | 57.9 | 62.2 | 58.2 | 54.2 | 65.6 |
Swift Sampling remains highly competitive with all query-agnostic baselines while operating at a negligible 1.02× inference cost, with the strongest gains on the long-video subsets.
Swift Sampling consistently outperforms uniform sampling across all frame budgets K, with significant gains on longer videos and under highly constrained budgets. As the frame budget tightens, identifying temporal surprises becomes critical for model reasoning.
| Budget K | MLVU (all) | MLVU (≥30 min) | ||
|---|---|---|---|---|
| Uniform | Ours | Uniform | Ours | |
| 32 | 64.7 | 65.6 | 50.0 | 54.2 |
| 16 | 61.6 | 63.9 | 47.9 | 50.0 |
| 8 | 58.6 | 60.3 | 50.0 | 54.2 |
| 4 | 54.4 | 56.7 | 45.8 | 58.3 |
| 2 | 51.8 | 54.0 | 43.8 | 54.2 |
On videos longer than 30 minutes, Swift Sampling improves over uniform sampling by 12.5 points at K=4 and 10.4 points at K=2.
Token compression. We integrate Swift Sampling into UniComp, the current state-of-the-art token-compression method, by replacing its default uniform frame selection. Swift Sampling consistently boosts UniComp's accuracy across all retention ratios r, achieving a peak gain of +1.6 points on MLVU (r = 0.15). It offers a drop-in improvement for token-compression pipelines.
Video captioning. We evaluate Swift Sampling on LLaVA-OneVision on the TempCompass benchmark, where improved frame selection is expected to yield more informative captions. Swift Sampling improves captioning performance across nearly all categories, but struggles on attribute change.
Other downstream tasks in Video-MME. Analyzing performance by task category, Swift Sampling excels in reasoning-intensive tasks: Spatial Reasoning (+5.4%), Action Reasoning (+3.9%), Temporal Reasoning (+2.8%), and Action Recognition (+2.2%).
Frames selected by Uniform sampling, Cosine Uniqueness, and Swift Sampling from a 128-frame candidate pool.


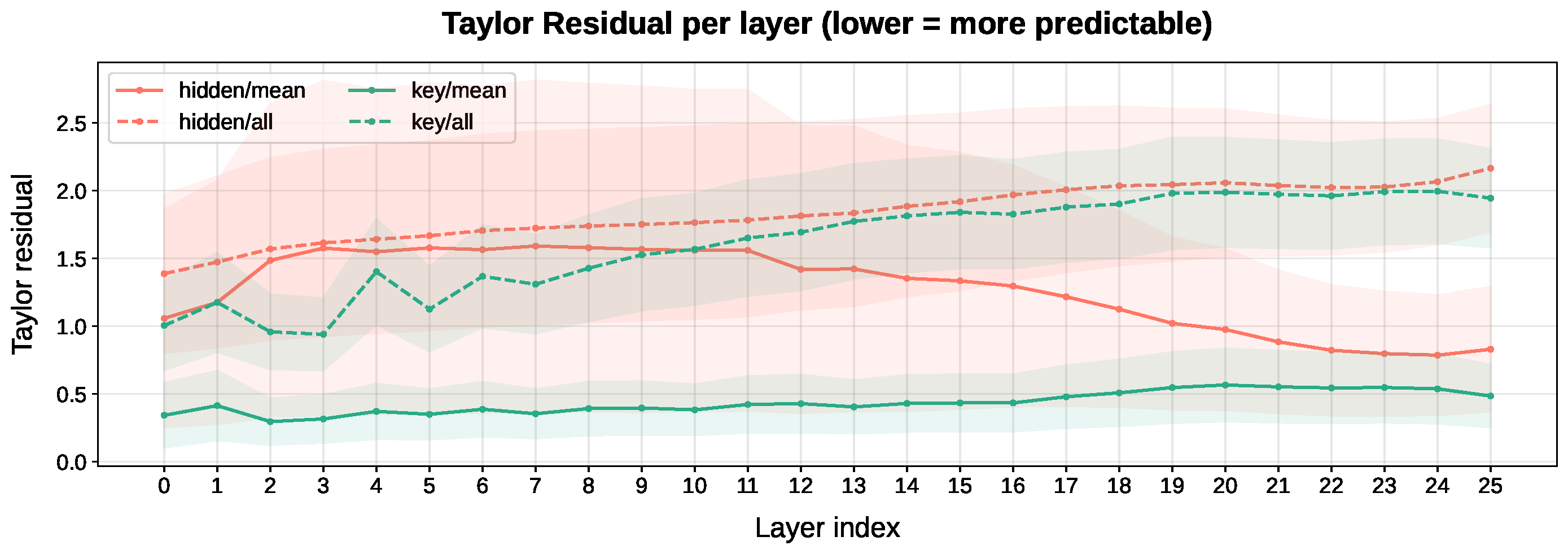
Choice of feature layer and type. We study which layers and feature types yield the most predictable temporal dynamics. Mean-pooled key features in the earliest layers produce the lowest residuals: early-layer features provide stable, low-level scene representations that evolve smoothly, making them highly predictable yet sensitive to sudden surprises. We use ℓ = 0 as our default choice.
Choice of feature pooling. We aggregate each frame's token grid into an S×S patch grid before computing the residual, sweeping S ∈ {1, 2, 4, 7, 14}. Global mean pooling (S = 1) achieves the best overall performance; finer grids dilute the temporal signal, presumably because local residuals are dominated by texture noise and camera jitter.
Effect of Taylor expansion order. VQA accuracy improves sharply from N = 1 to N = 3 across all three benchmarks, after which performance saturates. Low-order terms effectively capture the majority of predictable local dynamics, so we adopt N = 3 as the default.
Additional examples across Video-MME, LongVideoBench, and MLVU, including Taylor-residual visualizations.







@article{kim2026swift,
title = {Swift Sampling: Selecting Temporal Surprises via Taylor Series},
author = {Kim, Dahye and Sachdeva, Bhuvan and Uppal, Karan and Gupta, Naman
and Balasubramanian, Vineeth N. and Ghadiyaram, Deepti},
journal = {arXiv preprint arXiv:2605.22678},
year = {2026}
}